AAAI 2018
Abstract
- 인간 신체의 골격 움직임은 인간 동작 인식을 위해 중요한 정보를 전달함
- 기존 골격 모델링 방법들은 일반적으로 수작업으로 정의된 신체부위나 순회 규칙에 의존해 와서 표현력이 제한되고 일반화에 어려움이 있었음
- 동적 골격을 모델링하기 위한 Spatial Temporal Graph Convolutional Networks(ST-GCN)을 제안함
- 데이터로부터 공간적 패턴과 시각적 패턴을 자동으로 학습함으로써 기존 방법의 한계를 극복
Introduction
- 모달리티를 체계적으로 탐구하며 동적인 골격을 모델링하고 동작 인식에 활용하기 위한 원리적이고 효과적인 방법을 개발하는 것을 목표로 함
- 초기의 골격 기반 동작 인식 방법들은 각 시점의 관절 좌표를 단순히 특징 벡터로 구성하고 그 위에서 시간적 분석을 수행하는 방식이었음
- 관절들 간의 공간적 관계를 명시적으로 활용하지 않기 때문에 한계가 있음
- 관절들 간의 자연스러운 연결 구조를 활용하려는 새로운 방법들이 제안됨
- 대부분의 기존 방법들은 공간적 패턴을 분석하기 위해 수작업으로 정의된 신체 부위나 규칙에 의존함
- 다른 분야로 일반화하기 어려움
- 관절의 공간적 구성에 내재된 패턴과 시간적 동역학을 자동으로 포착할 수 있는 새로운 방법이 필요함
- Graph 신경망을 공간-시간 그래프 모델로 확장하여 동작 인식을 위한 골격 시퀀스의 일반적인 표현 방식을 설계하고자 함
- Spatial-Temporal Graph Convolutional Networks(ST-GCN)
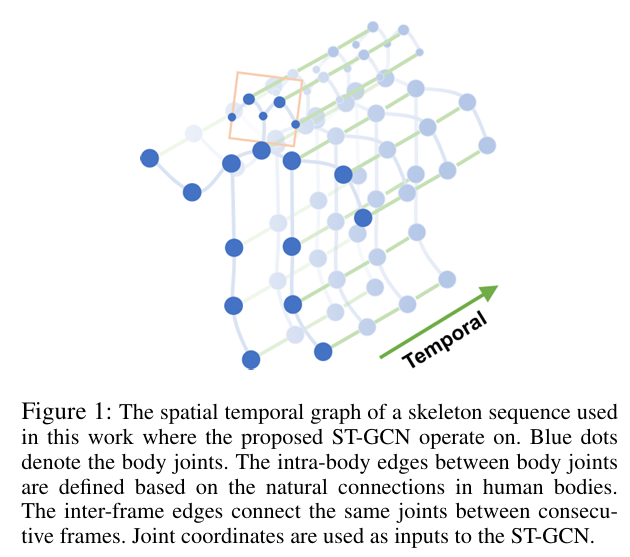
- 모델은 골격 그래프들의 시퀀스 위에 구성되며 각 노드는 인체의 하나의 관절에 해당함
- edge는 두 가지 유형으로 구성됨
- 관절들의 자연스러운 연결 구조를 따르는 공간적 간선(spatial edges)
- 연속된 시간 단계 사이에서 동일한 관절을 연결하는 시간적 간선(temporal deges)
- 이 구조 위에 여러 층의 spatial-temporal graph convolution(공간-시간 그래프 합성곱) 계층이 쌓이게 되며, 이를 통해 정보가 공간 차원과 시간 차원 양쪽을 따라 통합될 수 있음
본 연구의 주요 기여는 다음 세 가지로 요약됨
- 동적인 골격을 모델링하기 위한 일반적인 그래프 기반 정식화인 ST-GCN을 제안함. 그래프 기반 신경망을 적용한 최초의 연구
- 골격 모델링의 특수한 요구 사항을 충족하기 위해 ST-GCN에서 합성곱 커널을 설계하는 여러 원칙을 제안함
- 골격 기반 동작 인식을 위한 두 개의 대규모 데이터셋에서 실험한 결과 ,수작업으로 정의된 신체 부위나 순회 규칙에 의존한 기존 방법들보다 우수한 성능을 달성함, 수동 설계 노력은 상당히 줄였음
Spatial Temporal Graph ConvNet
- 신체 부위가 전체 골격이 아니라 국소 영역(local regions) 내에서 관절 궤적을 제한적으로 모델링하도록 만들기 때문에 성능 향상이 일어남
- 결과적으로 골격 시퀀스의 계층적 표현(hierarchical representation)을 형성함
- 이미지 객체 인식과 같은 작업에서는 계층적 표현과 국소성(locality)이 객체 부위를 수작업으로 정의해서 얻어지는 것이 아니라, CNN의 본질적 특성에 의해 자동으로 형성됨 (Krizhevsky, Sutskever, and Hinton 2012)
3.1 Pipeline Overview
- 골격 기반 데이터는 모션 캡처 장치나 비디오에서의 포즈 추정 알고리즘을 통해 얻을 수 있음
- 일반적으로 데이터는 프레임 시퀀스 형태, 각 프레임에는 관절 좌표 집합이 존재
- 관절을 그래프의 노드로 하고, 인체의 자연스러운 연결성과 시간 간 연결성을 간선으로 갖는 공간-시간 그래프(spatial temporal graph)를 구성함
- ST-GCN에 입력되는 데이터는 그래프 노드 상의 관절 좌표 벡터
- 2D 이미지 상의 픽셀 강도 값을 입력으로 사용하는 CNN과 유사하게 생각할 수 있음
- 여러 층의 spatial temporal graph의 convolution 연산이 입력 데이터에 적용, 점진적으로 그래프 상에서 더 높은 수준의 feature maps 생성. 최종 feature map은 표준 Softmax를 통해 해당 동작 범주로 분류됨
- end-to-end 방식으로 학습, backpropagation을 통해 최적화 됨.
3.2 Skeleton Graph Construction
- 골격 데이터를 공간 + 시간 그래프 형태로 정의하는 단계
- Skeleton sequence를 Spatial-Temporal Graph로 변환하는 단계
- 노드 정의(시간이 포함된 관절 그래프)
- 노드 = 사람 관절
- 각 프레임마다 관절 존재
- 시퀀스 전체를 하나의 그래프로 확장

- 간선 정의
- Spatial edge
- 같은 프레임 안에서 인체 구조에 따른 연결
- ex) shoulder ↔ elbow
- Temporal edge
- 연속 프레임 사이에서 같은 관절 연결
- ex) left wrist(t) ↔ left wrist(t+1)
- 공간 + 시간 연결을 모두 가진 하나의 큰 그래프
- 관절 간 관계 학습 가능
- 관절의 시간 변화 학습 가능
3.3 Spatial Graph Convolution
- 이미지 CNN의 픽셀은 grid(격자) 구조, 주변 픽셀 위치가 고정되어 있음
- 하지만 그래프는 이웃 개수가 다르고 위치 개념이 없음
- ! 그래프에서도 convolution처럼 이웃 노드들을 모아서 가중합 진행
- 출력 노드 feature의 기본 형태:
-


- Partition Strategy
- 그래프는 위치 개념이 없으므로 이웃 노드를 그룹으로 나눔
- ex) 자기 자신, 가까운 관절, 먼 관절
- 각 그룹마다 다른 weight를 적용 (CNN에서 커널 위치에 따라 weight를 다르게 쓰는 것과 대응됨)
- 공간 이웃 + 시간 이웃 모두 포함
- 관절 간 정보 전달, 시간 흐름 정보 전달
- 그래프에서 CNN처럼 이웃 노드를 모아 가중합하는 연산 정의

- Input Video: 원본 비디오(RGB)
- Pose Estimation: 각 프레임마다 사람 관절 추출 ( 영상 → 관절 좌표(skeleton) 시퀀스 )
- Spatial-Temporal Graph 구성
- 각 프레임의 관절을 같은 프레임 내 관절끼리 연결(Temporal 연결)/ 연속 프레임의 같은 관절끼리 연결(spatial 연결)
- 관절들을 공간+시간 그래프로 확장
- ST-GCN 적용
- 여러 층의 spatial-temporal graph convolution 수행
- 관절 간 관계 학습, 시간 흐름 학습, 고차원 feature 생성 ( 점점 더 추상적인 동작 표현으로 변환됨 )
- Action Classification: 최종 feature를 Softmax에 입력하여 행동 클래스 확률 출력
3.4 Partition Strategies
- spatial-temporal graph convolution의 high-level formulation(정식화)가 주어졌을 때, 라벨 맵 l을 구현하기 위한 분할 전략을 설계하는 것이 중요함
- Uni-labeling
- 가장 단순하고 직관적인 분할 전략은 이웃 집합 전체를 하나의 부분집합으로 두는 것
- 이 전략에서는 모든 이웃 노드의 feature 벡터가 동일한 가중치 벡터와 내적을 수행( Kipf and Welling (2017)에서 제안된 전파 규칙과 유사)
- 그러나 단일 프레임의 경우, 이 전략은 모든 이웃 노드 feature의 평균 벡터와 하나의 가중치 벡터를 내적하는 것과 동일함
- 지역적 차이를 잃어버릴 수 있기 때문에 skeleton 시퀀스 분류에는 최적이 아님
-
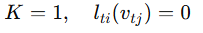
- Distance Partitioning
- 또 다른 자연스러운 전략은 루트 노드 vti로부터의 거리 d( ⋅, vti)에 따라 이웃을 분할하는 것
- D = 1 이므로 이웃 집합은 두 부분으로 나뉨
- 거리 0: 루트 노드 자체
- 거리 1: 나머지 이웃 노드
- 두 개의 서로 다른 가중치 벡터를 사용하게 되며, 관절 간 상대적 이동과 같은 지역적 차이를 모델링 할 수 있음

- Spatial Configuration Partitioning
- 인체 골격은 공간적으로 구조화되어 있으므로, 이 구조적 특성을 활용할 수 있음
- 루트노드
- centripetal(구심 그룹): 골격 무게중심에 더 가까운 노드
- centrifugal(원심 그룹): 무게중심에서 더 먼 노드
- 한 프레임에서 모든 관절 좌표의 평균을 무게중심으로 정의함
- 신체 움직임이 구심성과 원심성 움직임으로 나뉠 수 있다는 점에서 영감 받음
- 더 정교한 분할 전략이 더 좋은 모델링 능력과 인식 성능으로 이어질 것으로 기대됨

ri는 관절 i가 무게중심으로부터 가지는 평균 거리
- 인체 골격은 공간적으로 구조화되어 있으므로, 이 구조적 특성을 활용할 수 있음
3.5 Learnable Edge Importance Weighting
- 사람이 동작을 수행할 때 관절은 그룹 단위로 움직이지만, 하나의 관절은 여러 신체 부위에 동시에 포함 될 수 있음
- 이러한 경우 각 edge는 서로 다른 중요도를 가져야 함
- 따라서 ST-GCN 레이어에 학습 가능한 마스크 M을 추가함
- 마스크는 각 공간 간선의 중요도를 학습하여, 이웃 노드에 전달되는 feature 기여도를 조절함 (인식 성능을 추가적으로 향상시킴)
3.6 Implementing ST-GCN
- 그래프 합성곱 구현은 일반적인 2D/3D 합성곱보다 복잡함
- 단일 프레임의 경우 인체 관절 연결은 인접행렬 A와 단위행결 I로 표현됨

- 그래프 합성곱은 1 x Γ(Gamma) 2D convolution 수행, 정규화된 adjacency 행렬과 곱셈
- 다중 부분집합의 경우
- Adjacency 행렬을 여러 개 Aj로 분해
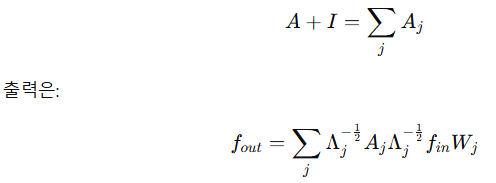
- Edge Importance Weighting 구현
- 각 adjacency 행렬에 학습 가능한 마스크 M을 곱함

- 네트워크 구조 및 학습
- ST-GCN 레이어 9개
- 채널 구성: 64 → 128 → 256
- Temporal kernel size = 9
- 4번째, 7번째 레이어 stride = 2
- ResNet 구조 적용
- Dropout 0.5
- 마지막에 Global Pooling
- SGD 학습
- learning rate 0.01 → 10 epoch마다 0.1배 감소
- 데이터 증강(Kinetics)
- Random moving (affine 변환으로 카메라 움직임 시뮬레이션)
- Random fragment sampling

Experiments
- skeleton 기반 행동 인식 실험을 통해 ST-GCN의 성능 평가
- 데이터셋 (매우 다른 특성을 가진 두 개의 대규모 행동 인식 데이터셋에서 실험 수행)
- Kinetics 인간 행동 데이터셋 (Kinetics) (Kay et al. 2017): 현재까지 가장 큰 규모의 비제약(unconstrained) 환경 행동 인식 데이터셋 (240,000개의 학습 클립/ 20,000개의 검증 클립)
- NTU-RGB+D (Shahroudy et al. 2016): 실내 환경에서 수집된 3D 관절 주석이 제공되는 가장 큰 행동 인식 데이터셋
- Kinetics 데이터셋에서 상세한 ablation study를 수행하여 제안된 모델 구성 요소들이 인식 성능에 어떤 기여를 하는지 분석
- ST-GCN의 인식 성능을 기존 최신(state-of-the-art) 방법들과 다른 입력 모달리티들과 비교
- 비제약 환경에서 얻은 결과가 일반적인지 확인하기 위해, 제약 환경인 NTU-RGB+D에서도 실험을 수행하고 기존 최신 방법들과 비교
- PyTorch 딥러닝 프레임워크에서 수행, 8개의 TITAN X GPU를 사용
4.1 Dataset & Evaluation Metrics
- Skeleton 입력 구성 방식
- 본 연구는 skeleton 기반 행동 인식에 초점을 맞추므로, 원본 RGB프레임은 사용하지 않고 픽셀 좌표계에서 추정된 관절 위치만을 입력으로 사용함
- 관절 위치를 얻기 위해:
- 모든 비디오를 340x256 해상도로 리사이즈
- 프레임 rate를 30FPS로 변환
- 공개된 OpenPose 툴박스 (Cao et al. 2017b) 를 사용하여 각 프레임에서 18개의 관절 위치 추정 (OpenPose는 각 관절에 대해 2D좌표 X,Y / 신뢰도 점수 C를 제공함)
- 각 관절은 (X,Y,C)튜플로 표현, 하나의 skeleton 프레임은 18개의 튜플 배열로 구성됨
- Multi-person 처리
- 한 클립에 여러 사람이 존재하는 경우, 평균 관절 신뢰도가 가장 높은 상위 2명을 선택
- T 프레임을 가지는 하나의 클립은 skeleton 시퀀스로 변환됨
- 입력 텐서 표현
- 단순화를 위해 모든 클립은 시퀀스를 반복 재생하여 T=300이 되도록 padding
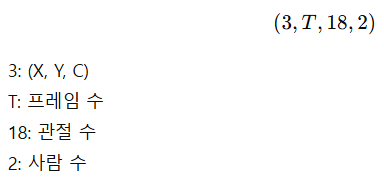
- 평가 지표
- Top-1 accuracy
- Top-5 accuracy
- 입력 데이터
- NTU-RGB+D에서 제공되는 주석은:
- 3D 관절 좌표(X,Y,Z)
- 카메라 좌표계 기준
- Kinect depth 센서를 통해 추출
- 각 skeleton 시퀀스는 25 개의 관절을 가짐
- 각 클립에는 최대 2명까지만 존재함
- 평가 프로토콜
- 데이터셋 저자들은 두 가지 벤치마크를 제안함
- 1. Cross-Subject (X-sub)
- 40,320개 클립: 학습
- 16,560개 클립: 평가
- 2. Cross-View (X-View)
- 37,920개 클립: 학습
- 18,960개 클립: 평가
4.2 Ablation Study
- ST-GCN이 왜 좋은지 구성 요소별로 실험하여 증명
- (공간 그래프가 진짜 필요한지, Partition 전략이 왜 중요한지, Edge importance는 왜 필요한지)
- Spatial temporal graph convolution
- 필요성 검증을 위해 비교:
- Baseline TCN
- 관절을 그냥 이어붙이고 시간축만 CNN 적용
- 사실상 fully connected graph 에서 weight를 공유 안 한 것과 같음
- Local Convolution
- 그래프 구조는 사용하지만 weight 공유는 안 함
- ST-GCN
- 자연스러운 인체 연결 + .weight 공유
- Baseline TCN보다 훨씬 좋음
- 단순 temporal convolution만으로는 부족함
- 성능 차이의 원인은 희소한 자연 연결 구조, weight 공유 (자연스러운 관절 연결 구조를 쓰는 것이 중요함)
- Partiton Strategy
- 3가지 전략 비교:
- Uni-labeling
- 이웃 다 같은 weight
- convolution 전에 feature를 평균 내는 것과 동일함
- Distance partition
- 거리 기준 분리
- Spatial configuration
- 중심/바깥 기준 분리
- 여러 subset으로 나누는 게 훨씬 좋음
- 이웃 관절을 어떻게 나누냐에 따라 성능이 좌우됨
- Learnable edge importance weighting
- 각 edge마다 중요도를 학습하게 하여 성능이 1%이상 추가 상승
- → 모든 관절 연결이 동일하게 중요하지 않음
- 모델이 어떤 관절 연결이 더 중요한지, 덜 중요한지 자동으로 학습
성능 향상의 원인:
- 공간 구조를 반드시 써야 함
- 이웃을 구분해야 함
- 관절 연결 중요도를 학습해야 함

4.3 Comparison with State of the Arts
- ST-GCN이 SOTA 방법들보다 좋은지, 서로 다른 환경에서도 잘 작동하는지 검증
- Kinetics
- Skeleton 기반 방법들:
- Hand-crafted feature 방식
- Deep LSTM
- Temporal ConvNet
- RGB 모델 (참고용)
- Optical Flow 모델 (참고)
- 비교 결과:
- ST-GCN이 기존 skeleton 기반 모델보다 확실히 좋음
- RGB/Flow 보다는 낮음
- (Kinetics는 물체, 장면, 사람과의 상호작용을 인식해야하는 클래스가 많아서 Skeleton만으로는 부족한 클래스가 존재함)
- Kinetics에서 30개 motion 중심 클래스만 추려서 실험 진행
- Skeleton 모델과 RGB 모델 성능 차이가 거의 줄어듦
- 순수 body motion 문제에서는 skeleton이 거의 RGB 수준

- Skeleton 기반 방법들:
- NTU-RGB+D
- 실내, 카메라 고정, 3D 관절 데이터, 정제된 환경 데이터셋
- ST-GCN이 기존 SOTA보다 좋음
- LSTM 계열보다 높음
- 구조도 더 단순함
- 제약 환경과 비제약 환경 모두에서 잘 작동함(모델이 데이터 특성에 강건함)

- 추가 분석
- RGB + ST-GCN이 RGB 단독보다 더 좋음
- RGB + Flow + ST-GCN이 가장 좋음
- Skeleton은 단독으로는 RGB보다 약할 수 있지만 동작 정보는 더 정확하게 잡음

검증 결과 요약
- ST-GCN은 기존 skeleton 모델보다 확실히 강함
- 순수 motion 문제에서는 매우 강력
- 다양한 환경에서 잘 작동함
- Skeleton은 RGB와 보완적 정보
오늘은 Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition(ST-GCN) 논문을 읽어봤습니다. 수식과 단계가 많고 복잡해 이해하는 데 시간이 좀 걸릴 수는 있으나, 실험 방법에 대한 자세한 설명과 보충 비교 실험까지 포함되어있는 논문이라서 시간을 들여 읽어보아도 충분한 가치가 있다고 생각됩니다.
이 논문은 Skeleton 시퀀스를 spatial temporal graph로 표현하고, 그 위에서 graph convolution을 수행하는 ST-GCN을 제안했습니다. 관절 간 공간 관계와 시간적 움직임을 동시에 학습하여 기존 LSTM/TCN 기반 skeleton 모델보다 우수한 성능을 달성했습니다. 특히 순수 action motion 문제에서 강력한 표현력을 보였습니다.
이 논문의 핵심 기여는 다음과 같습니다.
- Spatial-Temporal Graph Convolution 제안
- Skeleton을 그래프로 모델링하고, 공간 + 시간 정보를 동시에 처리하는 최초의 일반적(graph-based) 정식화 제시
- Graph Convolution Kernel 설계 전략 제안
- Partition 전략 (distance / spatial configuration) 도입
- Learnable edge importance weighting 추가
→ 단순 평균이 아닌 구조적 차이를 학습 가능하게 함
- 대규모 데이터셋에서 SOTA 성능 달성
- Kinetics, NTU-RGB+D에서 기존 skeleton 기반 방법들보다 우수한 성능 검증
- Skeleton 정보가 RGB와 보완적임을 실험적으로 증명
다음은 이 논문의 한계점 입니다.
- Fine-grained motion 강도 구분에 약할 수 있음
- ST-GCN은 걷기vs점프, 앉기vs서기와 같은 완전히 다른 동작을 구분하는 문제를 위해 설계됨
- 미세한 velocity magnitude 차이를 직접적으로 모델링하진 않음
- 관절 좌표 기반이라 Velocity/Acceleration을 직접 모델링하지 않음
- 입력에 위치 정보만 있어서 속도나 가속도는 모델이 간접적으로 학습해야 함
- 소규모 데이터셋에서 과적합 위험
- GCN 계열 모델은 파라미터 수가 많아서 데이터셋에서는 overfitting이 우려됨
'논문리뷰' 카테고리의 다른 글
| Accurate baseball player pose refinement using motion prior guidance (0) | 2026.02.11 |
|---|---|
| Utilization of Inertial Measurement Units for Determining the Sequential Chain of Baseball Strike Posture (0) | 2026.02.10 |
| FedMeta (0) | 2024.05.25 |
| Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 논문 리뷰 (0) | 2024.05.15 |